Abstract
Music-driven dance video generation aims to synthesize expressive human motion that is temporally aligned with music while maintaining high visual fidelity. Existing methods still struggle to generate dance videos that simultaneously exhibit expressive motion and high visual quality, largely due to limited dance-specific data and the difficulty of integrating music into video generation foundation models.
We introduce CIPE-Dance, a large-scale Internet-sourced dance video dataset with choreography-informed text annotations, and propose OmniDance, a framework-level recipe for integrating music into a TI2V foundation model without sacrificing controllability or visual fidelity. OmniDance supports unified TI2V, MI2V, and MTI2V generation through depth-aware specialization, anchored curriculum learning, and modality-specialized time-dependent CFG.
Overview Video
Video
Dataset
CIPE-Dance
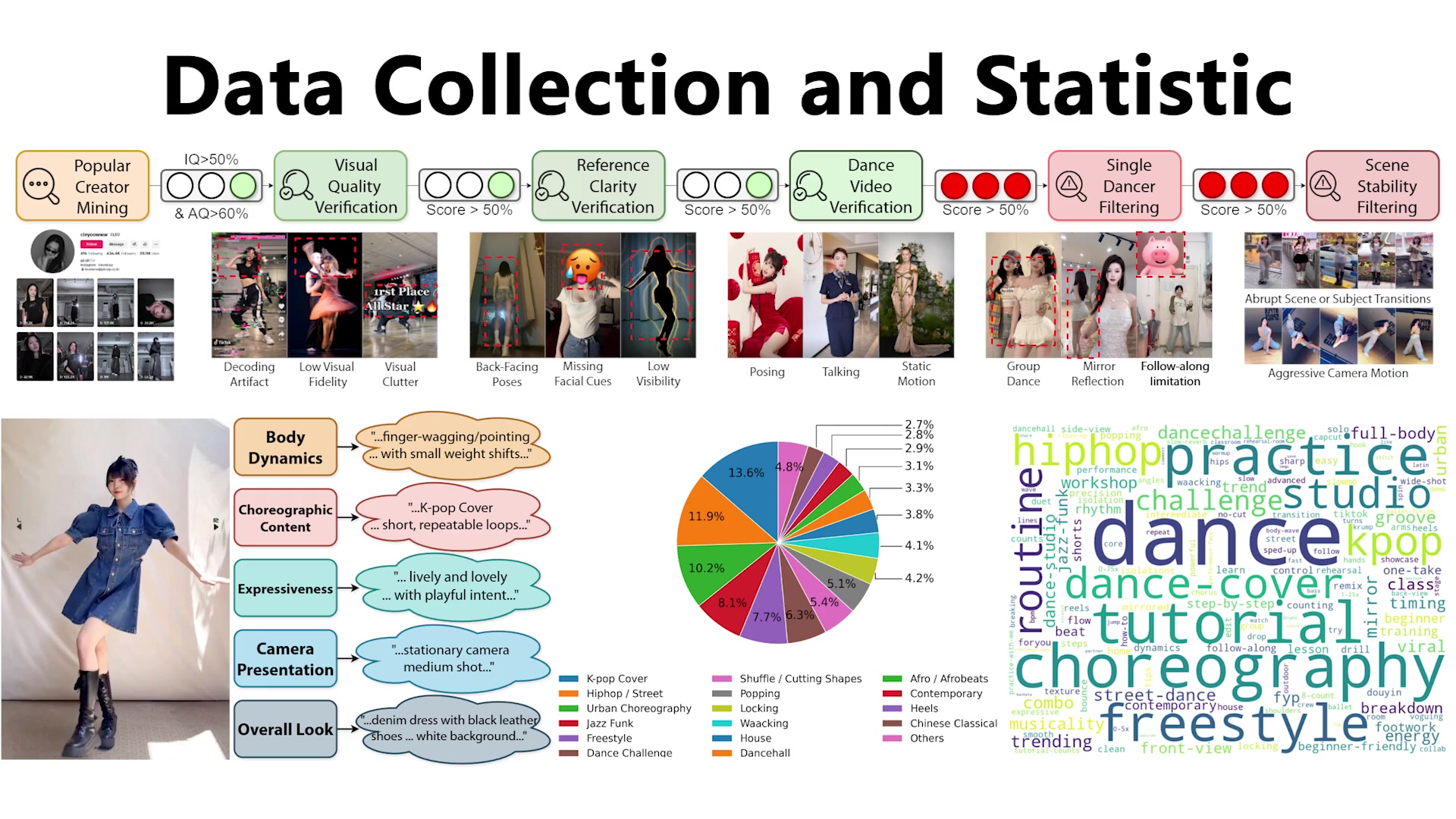
300K
high-quality clips
400+
video hours
30+
dance genres
5
annotation aspects
Method
OmniDance Framework
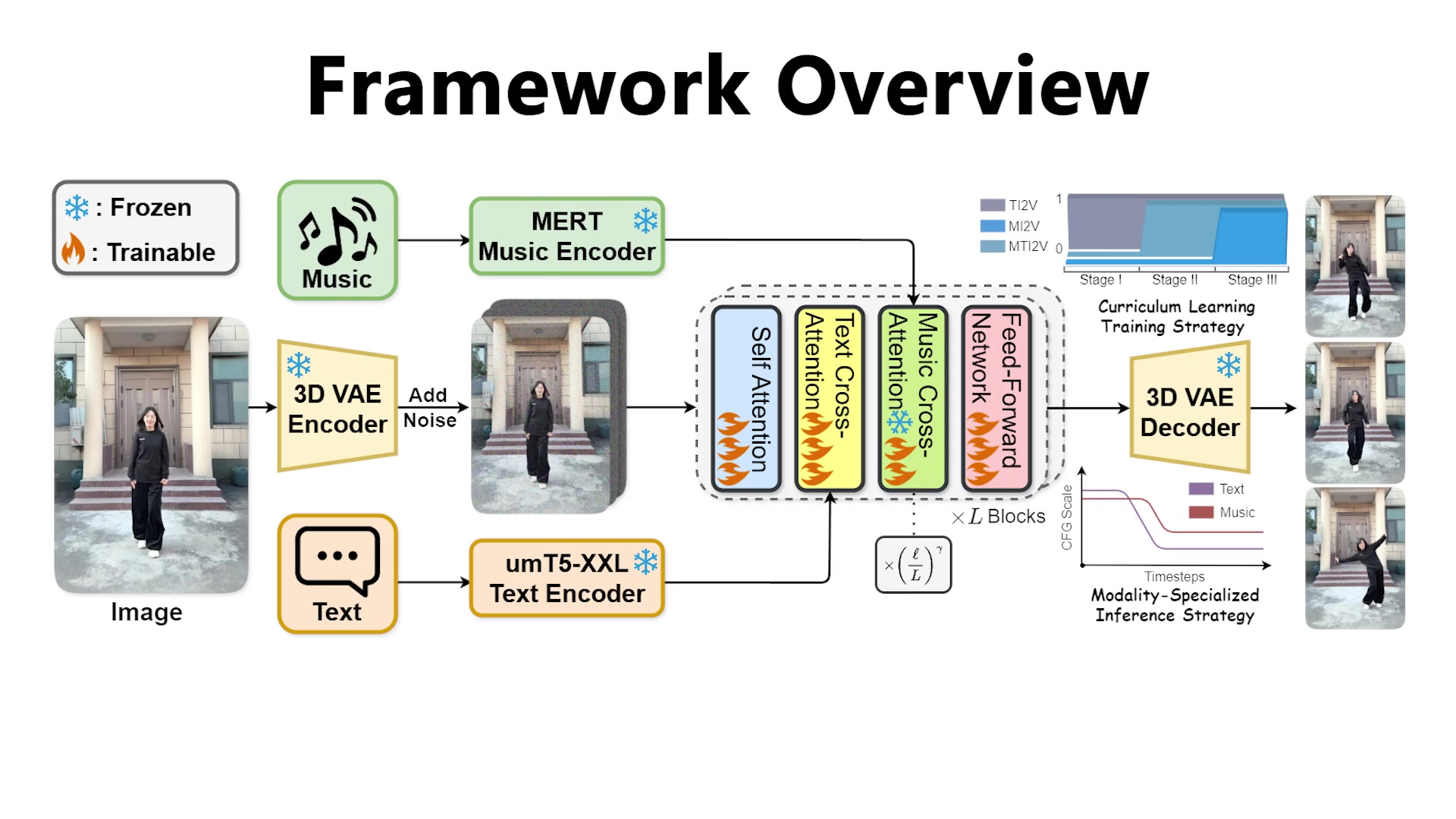
Curriculum Learning Training Strategy
Modality-Specialized Inference Strategy
Results
Generation Results
TI2V
Text + Image to Video
MI2V
Music + Image to Video
MTI2V
Music + Text + Image to Video
Citation
BibTeX
@article{omnidance2026,
title={OmniDance: Multimodal Driven Dance Video Generation with Large-scale Internet Data},
author={Yang, Kaixing and Zhu, Jiashu and Tang, Xulong and Peng, Ziqiao and Zhang, Xiangyue and Chen, Chubin and Wang, Puwei and Wu, Jiahong and Chu, Xiangxiang and Liu, Hongyan and He, Jun},
journal={ECCV},
year={2026}
}