MeanFlow Few-Step Generation
Predicts interval-averaged velocity for stable, high-fidelity sampling.
ECCV 2026
MeanFlow for Efficient and Refined 3D Dance Generation
1Renmin University of China 2Malou Tech Inc 3Wuhan University 4Tsinghua University
Abstract
Music-to-dance generation translates auditory signals into expressive human motion, yet existing approaches still struggle to balance refined 3D motion quality with strict inference budgets. FlowerDance is designed for both physically plausible, artistically expressive motion and efficient generation in speed and memory usage.
FlowerDance combines MeanFlow with Physical Consistency Constraints for high-quality few-step sampling, and uses a lightweight non-autoregressive BiMamba backbone with Channel-Level Fusion for long-horizon music-to-dance synthesis. It also supports motion editing through time-decayed soft masking, enabling users to refine generated dance sequences interactively.
Overview Video
Method
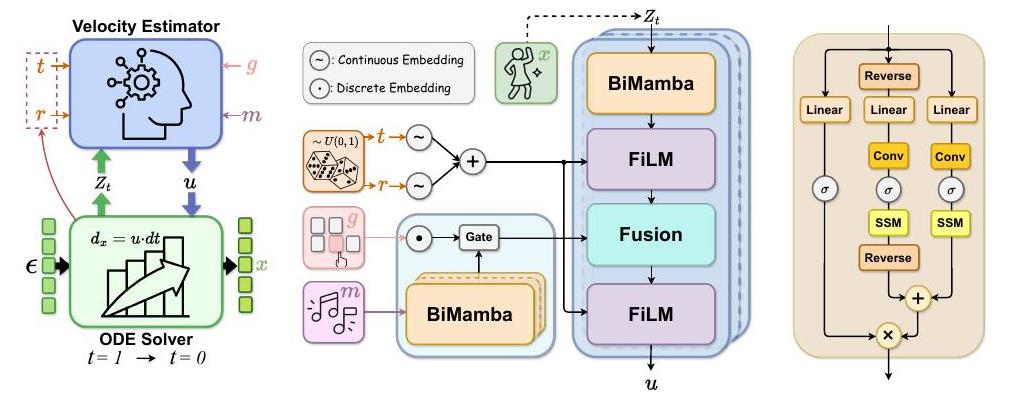
Predicts interval-averaged velocity for stable, high-fidelity sampling.
Regularizes reconstructed motion, velocity, and 3D joints toward plausible kinematics.
Uses a lightweight non-autoregressive backbone for long-horizon music-motion alignment.
Efficiency

Results
Citation
@inproceedings{yang2026flowerdance,
title={FlowerDance: MeanFlow for Efficient and Refined 3D Dance Generation},
author={Yang, Kaixing and Tang, Xulong and Peng, Ziqiao and Zhang, Xiangyue and Chen, Chubin and Zhou, Xukun and Wang, Puwei and Liu, Hongyan and He, Jun},
booktitle={European Conference on Computer Vision (ECCV)},
year={2026}
}